You get what you ask for. Because you are part of the computation.
What changes inside the model when you change who's talking
Different users get different results from the same AI model. The reasons are many. I designed an experiment for one of them: whether the style of human engagement produces a measurable structural difference in the model's computation.
I traced what the LLM was computing internally while two different styles of users engaged with it. The findings carry a recommendation. This is the short version; the methodology and the numbers live in a preprint.
Looking inside the model while it thinks
A quick mental model of how an LLM works: you type a prompt; the system breaks it into tokens (numbers); those numbers run through a vast network of weights (the billions of learned numbers the network discovered during training on a large corpus of human internet text); the output is more numbers, which get translated back into words. The network itself only sees numbers and replies in statistical probabilities, which is what makes the LLM probabilistic, or stochastic. Human language is just the interface on either end of the computation.
Here's the catch: between the input layer where you type and the output layer where the answer appears, the process is sealed. No one knows exactly what fires inside the network during inference: which parts, in what patterns, in response to what.
So I picked up a tool called the circuit tracer, an instrument that captures, for each word the model produces, which internal features were active and how they connected to each other to reach those words. You get an activation map: which features lit up, in which layers, and how they connected to produce the output.
Like an MRI taken while a brain is reading. Specific structures light up.
Run the tracer across enough conversations, sampled to represent different communication styles, and the patterns show you: why do different people get different results from the same model?
What I noticed
Some users lead the conversation; others delegate.
The leaders set the question themselves, add context the model could not have inferred, push back when the model drifts, and treat the exchange as collaborative work. They keep agency over the result and integrate the model into their cognitive process. The delegators hand the model a task, often through a scaffolded or curated prompt, frequently in corporate or business settings where reproducibility across shifts is the priority (call centers, support roles), and step back. They treat the exchange as input-in / output-out, the way you would query a database, a spreadsheet, or a calculator.
I pulled matched pairs from these two patterns. I'm calling the first type Navigator, holding agency and integrating the model into their thinking. I'm calling the second Operator, focused on transactional commissioning: ask for something, take it, apply. I matched the segments as closely as possible by domain and task, so the main contrast was communication style.
Navigators went deeper. They directed the model when they were not satisfied with the response, or when they noticed model drift, model bias, or early signs of hallucination. They corrected. They asked. They pushed back. When the model responded, they sometimes asked for a contrarian position. Operators stayed in production mode. They either used a scaffolded prompt or accepted the response, with or without feedback to the model, and simply moved on to the next question.
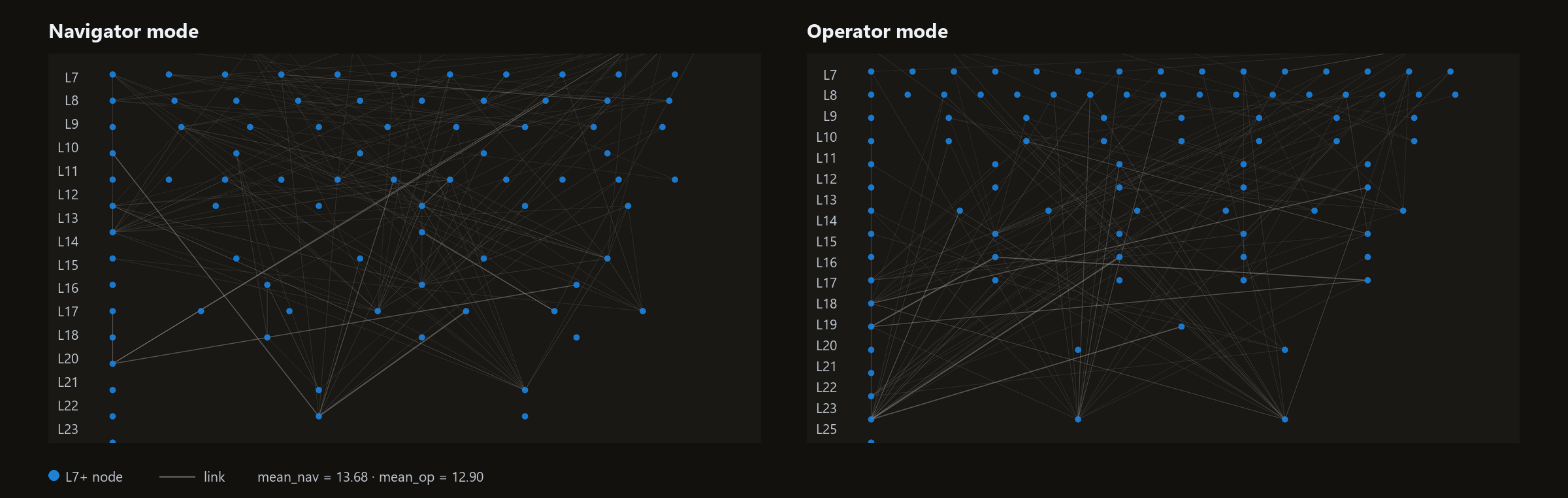
I ran the pairs through the circuit tracer. The difference was stable. The internal state when the user was leading looked structurally different from when the user was delegating, and the pattern held across topics, task types, and iterations.
The Navigator pattern reached deeper into the network, closer to where the model does its more abstract work. Across 17 matched pairs, 15 showed this depth shift in the same direction; the magnitude was small (about +0.4 layers on average within a 19-layer range) but consistent. A secondary signal showed up in the balance of positive versus negative connections: Navigator traces tilted slightly more positive.
The Operator pattern stayed shallower in the layer stack, and the positive/negative balance was more even.
The two patterns suit different work. Operator routing fits transactional questions where the answer is the same regardless of who asks: what's the capital of France, reformat this list, summarize this paragraph. Navigator routing is what the model does when what the user brings shapes what comes back.
Brief methodology
I pulled matched pairs from WildChat, a public dataset of millions of real human-AI conversations, and classified them for Navigator vs Operator behavior. Where the dataset did not contain a naturally-occurring Operator match that met the standardisation criteria, I generated the Operator counterpart on the same topic, to keep topic variance out of the comparison. Both sides ran through the circuit tracer. The full methodology and the indicator inventory live in the preprint.
What this looks like in practice
Here is the chat contrast in human turns only, what each person actually typed. The left column shows a user bringing their own thinking into the conversation; the right column shows a user commissioning outputs.
Navigator
Same topic. Different human."Again, this sounds similar to feudalism in Europe except the people are not required to pay their rules in service or allegiance; they are allowed to use and live off their land out of religious reasons."Scaffolding Refines the frame himself.
"Can the land allocation practices of the Mayans and later Mexica be described as 'socialist' or even 'communist' by modern standards. I'm not saying the Mayans and Aztecs were socialist or communist, obviously those ideologies did not exist in Classical and Postclassical Mesoamerica. I'm just saying, isn't it interesting that the practices share similarities to the modern idea of socialism and communism as described by Karl Marx?"Agentic redirection Proposes the frame and pre-empts the model's likely objection.
"So could anyone just build a house and live on the property of the Ajaw without paying fees, performing mandatory labor, or serving in the military? Essentially, freeloading was allowed in the Classical Mayan city-states."Stakes question Tests an implication.
"I remember a gag for the 100th episode of Aqua Teen Hunger Force were it was mentioned that the number 100 held sacred significance to the Mayans. However, this is inaccurate, the number they were thinking of was 400 because the Mayans based their mathematical system on the number 20 rather than 10 like in the Europe."Correction Contributes outside knowledge.
Operator
Same topic. Different human."Explain how Mayan land allocation worked compared to European feudalism."Delegation
"Reformat this into a side-by-side comparison table."Format request
"Now do the same for Aztec land allocation."Format request
"Summarize the key differences across all three systems in 3 bullets."Format request
"Give me 5 quick facts about the Mayan number system."Delegation
"Expand each row of the Mayan vs European table into a short paragraph."Format request
"Now give me 5 quick facts about the Mayan calendar."Delegation
What this means for the user
Some users come to these models for a service: a question in, a ready answer out, applied to the task. Others come more diligent. They bring their own context. They push back. They ask for evidence, for the contrarian read, for what they might themselves be missing.
Everything the model does runs on statistical probability. It selects the next token from a distribution shaped by its training data. Ask a generically-shaped question, and the model tends to give you a high-probability answer from that distribution: the statistical compression of the internet text it absorbed. Bring your own thinking, your domain knowledge, your partial answers, your doubts, and you change the distribution. You activate different circuits, still statistically backed up but in a different distribution: rarer combinations of features, less-traveled pathways. The exchange is reciprocal: you get what you ask for. Feed it from your own biological neural network, and it routes through more of its own circuits in response.
The shorthand
Practical recommendation for everyday user: Make the model argue against you. Even on your strongest idea, even on your cleanest draft. Push your half-formed thinking in. You'll find what you missed.
More agency from the user pulls the computation into deeper, more structured pathways.
Whether that produces better output is something most of us already know from our own work. What this study adds is the structural correlate inside the network. The pattern you have noticed in the chat, made visible in the machine.